3 Часові ряди та їх візуалізація
Часовий ряд — це послідовність значень деякої змінної, що зареєстровані в певні моменти часу.
Розрізняють одновимірні та багатовимірні часові ряди. В першому випадку розглядається тільки одна змінна, в другому — декілька паралельних спостережень.
Часовий ряди можна записати, як \(y_t\), читається: часовий ряд \(y\) в момент часу \(t\).
В загальному випадку часовий ряд \(y_t\) розкладають на складові або компоненти:
тренд (\(T_t\)) — відповідає за довгострокову тенденцію зміни значень ряду (зростання, спадання, стагнація). Він може бути лінійним або нелінійним.
сезонна компонента (\(S_t\)) — відповідає за коливання часового ряду, які повторюються з постійною частотою. В цілому, якщо частота ряду щотижнева, щомісячна або щоквартальна і менше, вона може відображати сезонні коливання, тоді як для щорічних даних сезонність визначити неможливо.
циклічна компонента (\(C_t\)) — відповідає за довгострокові коливання ряду з непостійною регулярністю. Циклічні коливання охоплюють багаторічні періоди. Наприклад, це може бути пов’язано зі станом економіки країни (криза, спад, депресія тощо).
випадкова компонента (\(R_t\)) — стохастичні значення часового ряду, які неможливо врахувати.
3.1 Об’єкт tsibble
В мові програмування R є широкий спектр класів, за допомогою яких можна представити часові ряди: ts, zoo або xts. Але всі вони випадають з філософії “tiny-data,” що призводить до складнощів їх використання з сімейством пакетів tidyverse.
Рішенням цієї задачі займалися ряд вчених на чолі з професором кафедри економетрики та бізнес статистика університету Монаша Робом Хідманом. Вони розробили новий формат представлення часових рядів, який реалізований в пакеті tsibble (Wang, Cook, and Hyndman 2020). Згідно цього формату, часові ряди:
зберігаються в табличному вигляді;
містять в собі мінімум два стовпчики: значення кількісної змінної впорядкованої в часі (measurements) та часова шкала (index) — в який момент часу значення були записані;
може містити декілька часових рядів, які згруповані за ключовим змінними (key).
Для створення об’єкту tsibble використовується функція tsibble():
tsibble(year = 2017:2021,
variable = sample(c(50:100), 5),
index = year)
## # A tsibble: 5 x 2 [1Y]
## year variable
## <int> <int>
## 1 2017 75
## 2 2018 94
## 3 2019 92
## 4 2020 51
## 5 2021 52Для перетворення дата фрейму в tsibble використовується функція as_tsibble(), яка містить наступні аргументи:
x— об’єкт даних (це може бути вектор, матриця, дата фрейм тощо);key— групуюча змінна(і), яка(і) визначають кожен часовий ряд в даних;index— змінна з мітками часу;regular— логічний аргумент, який вказує на регулярність (TRUE) або нерегулярність (FALSE) спостережень в даних;validate— логічний аргумент, який перевіряє (TRUE) унікальність кожного спостереження в парах значеньkeyтаindex;.drop— логічний аргумент, якщо вказатиTRUEз таблиці будуть виключені спостереження, для яких не має групуючого значенняkey;tz— вказується часовий пояс спостережень;pivot_longer— логічний аргумент,TRUEпереводить дані в широкий формат,FALSEзалишає як є.
Перетворемо базовий часовий ряд AirPassengers з ts в tsibble:
class(AirPassengers)
## [1] "ts"
AirPassengers %>%
as_tsibble()
## # A tsibble: 144 x 2 [1M]
## index value
## <mth> <dbl>
## 1 1949 янв. 112
## 2 1949 февр. 118
## 3 1949 март 132
## 4 1949 апр. 129
## 5 1949 май 121
## 6 1949 июнь 135
## 7 1949 июль 148
## 8 1949 авг. 148
## 9 1949 сент. 136
## 10 1949 окт. 119
## # ... with 134 more rowsБачимо, що набір даних містить 144 щомісячних (1M) спостереження.
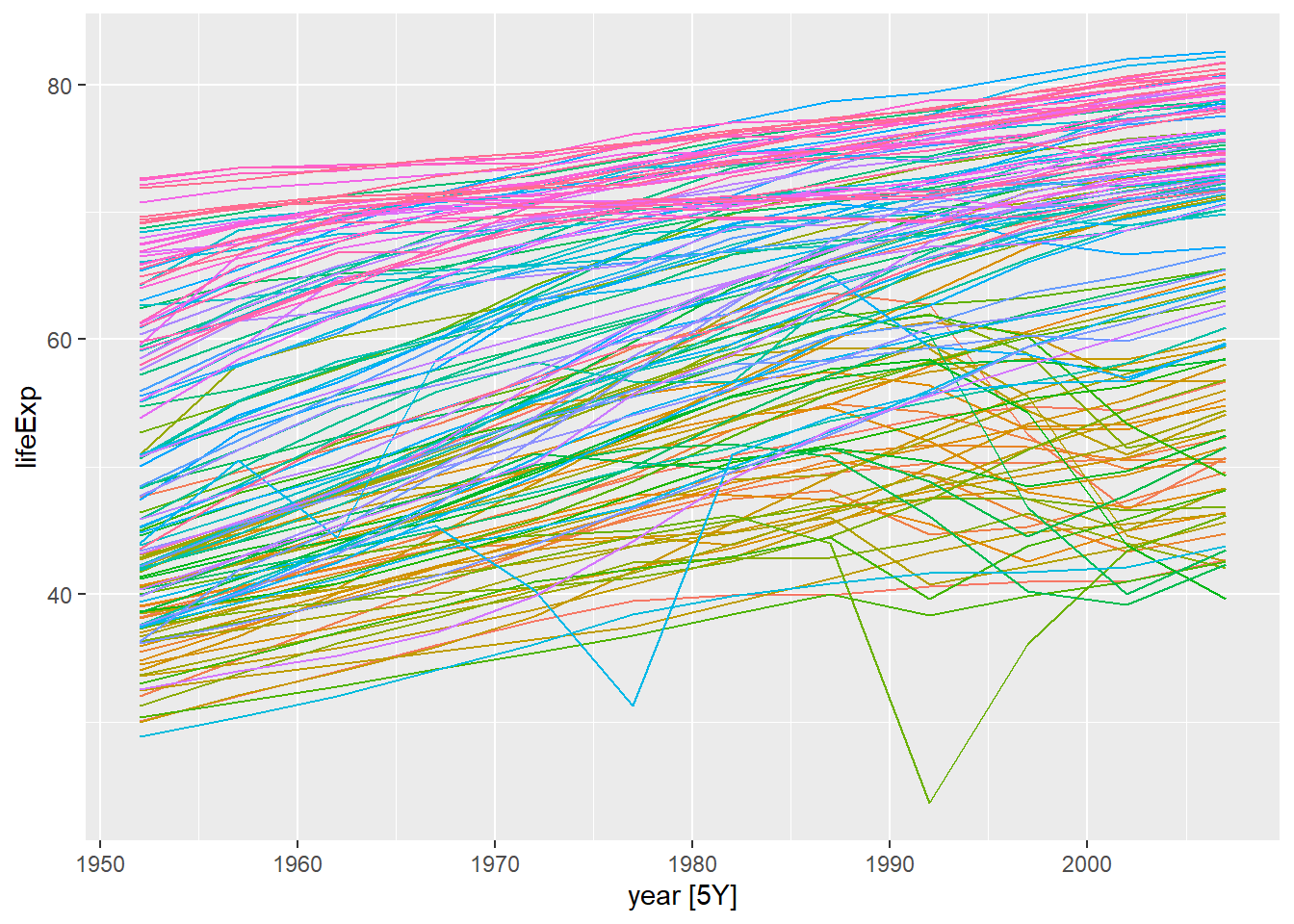
Розглянемо приклад перетворення дата фрейму gapminder у tsibble:
gapminder %>%
as_tsibble(key = c(country, continent),
index = year)
## # A tsibble: 1,704 x 6 [5Y]
## # Key: country, continent
## # [142]
## country continent year
## <fct> <fct> <int>
## 1 Afghanistan Asia 1952
## 2 Afghanistan Asia 1957
## 3 Afghanistan Asia 1962
## 4 Afghanistan Asia 1967
## 5 Afghanistan Asia 1972
## 6 Afghanistan Asia 1977
## 7 Afghanistan Asia 1982
## 8 Afghanistan Asia 1987
## 9 Afghanistan Asia 1992
## 10 Afghanistan Asia 1997
## # ... with 1,694 more rows, and
## # 3 more variables:
## # lifeExp <dbl>, pop <int>,
## # gdpPercap <dbl>В даному випадку, ми отримали tsibble, який містить дві ключові змінні та річні дані з інтервалом у 5 років (5Y).
Або подивимось на датасет з генерації відновлювальної електроенергії в Україні у 2021 році:
ua_energy <- vroom("https://git.io/J6Sjt", delim = ";") %>%
mutate(Time = parse_date_time(Time, orders = "H-dmy")) %>%
as_tsibble(index = Time)
ua_energy
## # A tsibble: 61,368 x 14 [1h]
## # <UTC>
## Time AES
## <dttm> <dbl>
## 1 2014-01-01 01:00:00 10728
## 2 2014-01-01 02:00:00 10606
## 3 2014-01-01 03:00:00 10515
## 4 2014-01-01 04:00:00 10475
## 5 2014-01-01 05:00:00 10427
## 6 2014-01-01 06:00:00 10473
## 7 2014-01-01 07:00:00 10469
## 8 2014-01-01 08:00:00 10493
## 9 2014-01-01 09:00:00 10479
## 10 2014-01-01 10:00:00 10455
## # ... with 61,358 more rows,
## # and 12 more variables:
## # TEC <dbl>, VDE <dbl>,
## # TES <dbl>, GES <dbl>,
## # GAES_GEN <dbl>,
## # CONSUMPTION <dbl>,
## # GAES_PUMP <dbl>, ...3.2 Пропущенні значення
При обробці непідготовлених даних досить часто зустріємося із ситуацією пропущених даних. Ця проблема особливо впливає на ефективність моделей прогнозування часових рядів.
Для перевірки наявності пропущених значень використовується функція has_gaps():
gapminder %>%
as_tsibble(key = c(country, continent),
index = year) %>%
has_gaps()
## # A tibble: 142 x 3
## country continent .gaps
## <fct> <fct> <lgl>
## 1 Afghanistan Asia FALSE
## 2 Albania Europe FALSE
## 3 Algeria Africa FALSE
## 4 Angola Africa FALSE
## 5 Argentina Americas FALSE
## 6 Australia Oceania FALSE
## 7 Austria Europe FALSE
## 8 Bahrain Asia FALSE
## 9 Bangladesh Asia FALSE
## 10 Belgium Europe FALSE
## # ... with 132 more rows
gapminder %>%
as_tsibble(key = c(country, continent),
index = year) %>%
autoplot(.vars = lifeExp) +
theme(legend.position="none")