1 Вступ до R
Мова програмування R — потужний інструмент, що широко використовується в різних сферах: статистика, візуалізація, наука про дані, машинне навчання, глибоке навчання тощо. Це безкоштовна система з відкритим кодом, з широкими можливостями, які досягаються за рахунок різноманіття покетів (packages) доповнень. R повністю безкоштовний та доступний для встановлення на більшість операційних систем. Крім того, є можливість працювати у хмарних додатках. В той же час, R ідеально підходить для проведення економетричних досліджень. Вивчити R не складно і цей розділ підготовить Вас до базових операцій.
1.1 Встановлення R
Варіантів роботи з мовою програмування R існує досить багато. Розберемо основні.
1.1.1 Встановлення на комп’ютер
Для початку необхідно встановити саму мову програмування під свою операційну систему:
Для роботи в R, також слів встановити інтегроване середовище розробки (IDE) RStudio, що значно підвищує зручність, швидкість та ефективність роботи.
Щоб встановити RStudio, завантажте останню версію інсталятора для Вашої операційної системи з сайту https://rstudio.com/products/rstudio/download/
1.2 RStudio
Я пропоную використовувати саме RStudio, оскільки це найзручніший інструмент для роботи з даними. При чому в ній можна працювати з різними мовами програмування, в тому числі й Python.
Якщо ваша операційна система — Windows, то після встановлення R та RStudio, на робочому столі у вас буде дві іконки:
 та
та 
Перша відноситься до самої мови програмування і не буде використовуватись в роботі, друга відноситься до RStudio і саме вона нам потрібна.
Після першого запуску RStudio ви побачите інтерфейс на рисунку 1.1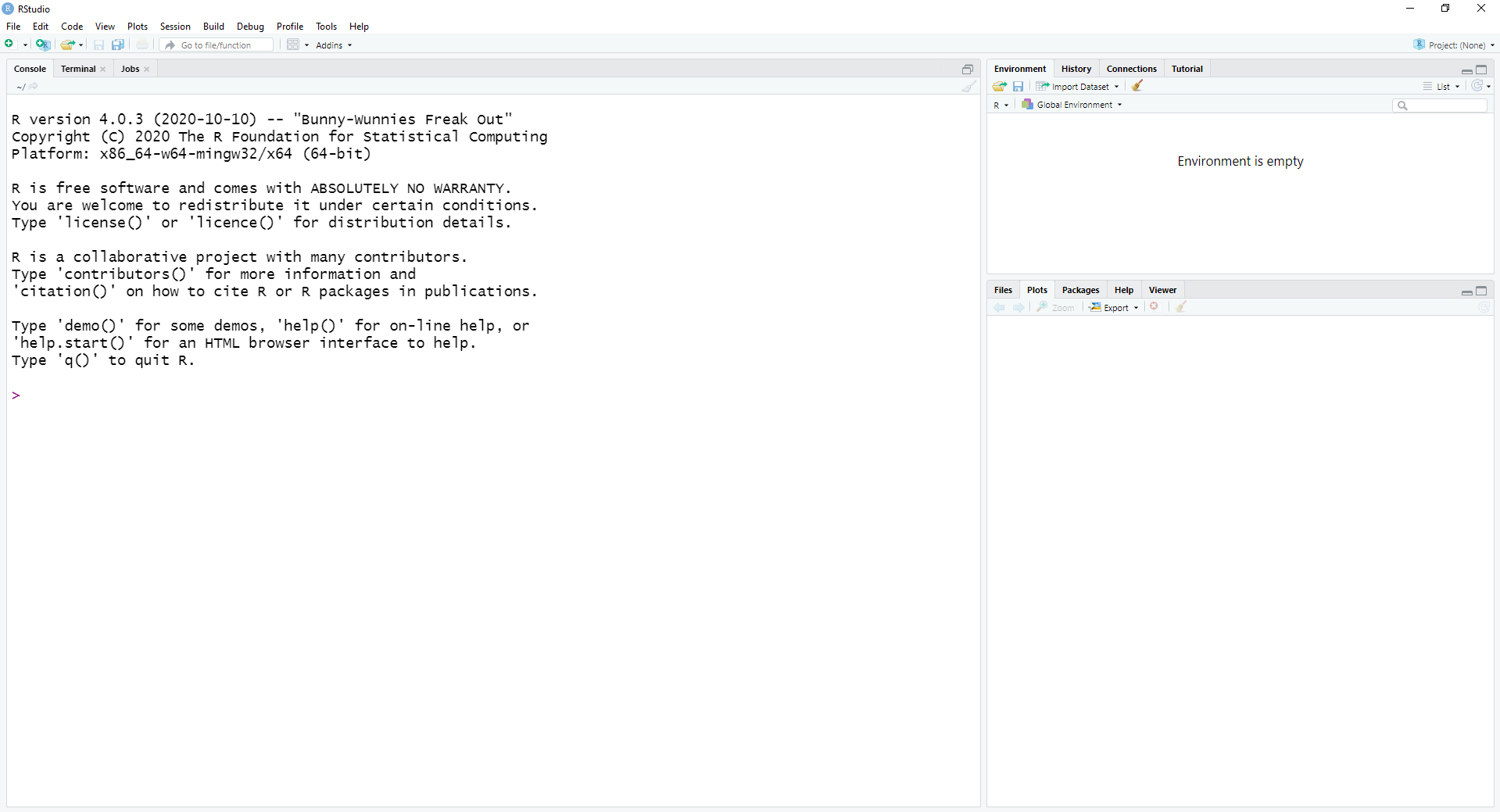
Рисунок 1.1: Базовий інтерфейс RStudio
Як правило код пишуть у скрипті (такий собі аналог текстового редактора), тож для його створення необхідно натиснути зелений хрестик в лівому верхньому куті та обрати пункт R Script або натиснути комбінацію клавіш Ctrl+Shift+N:
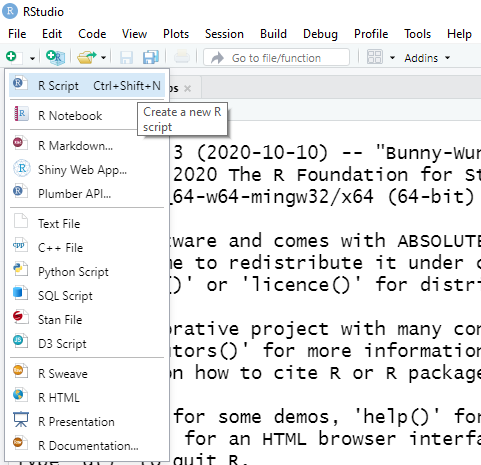
Рисунок 1.2: Створення скрипта в RStudio
Після чого, з’явиться додаткове вікно скрипту, де можна писати код, зберігати його та повертатися до нього за потреби.
Давайте розберемо отриманий інтерфейс: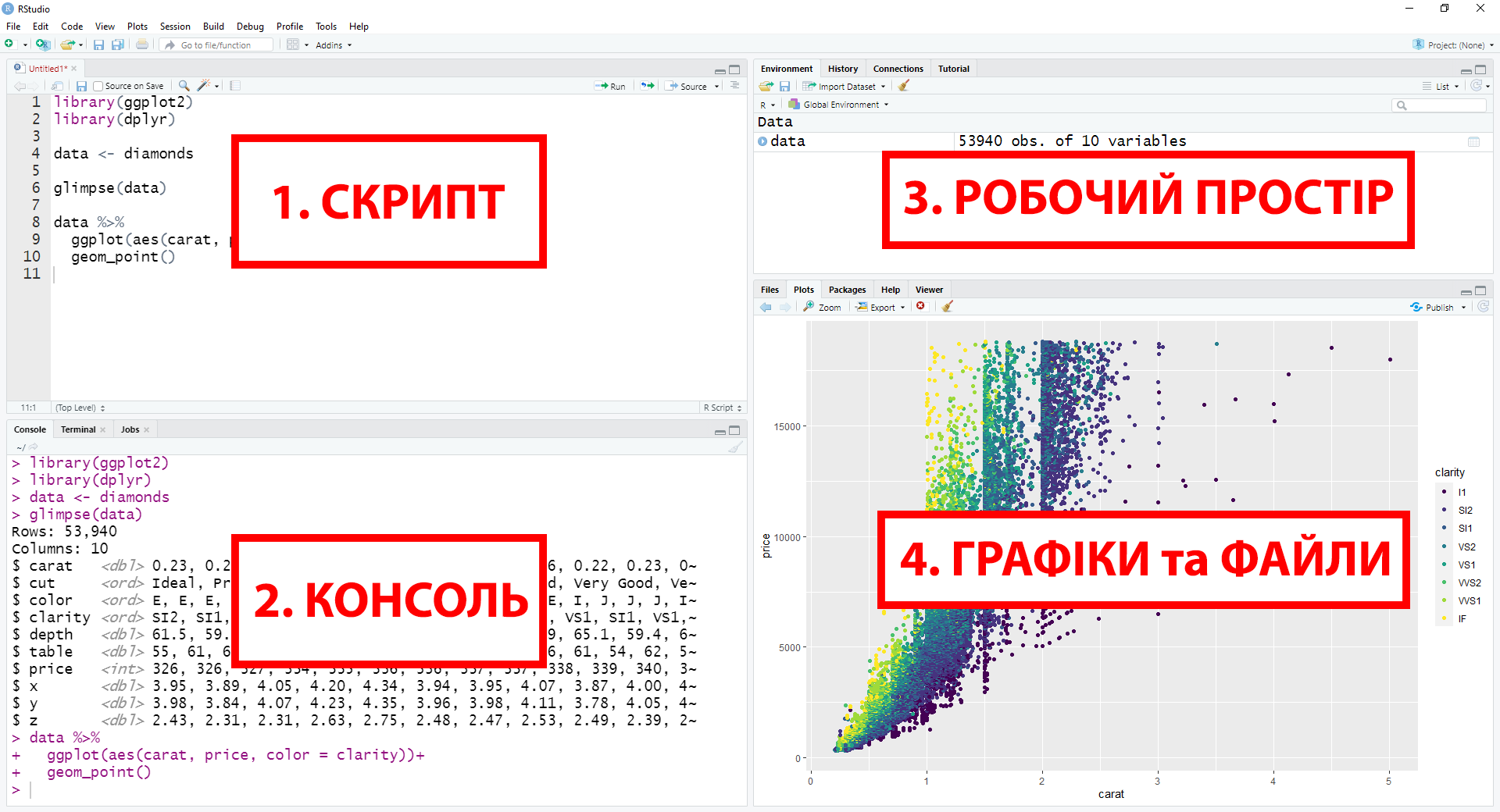
Рисунок 1.3: Інтерфейс RStudio
1. СКРИПТ — відбувається основна робота з кодом.
2. КОНСОЛЬ — повертаються результати виконання скриптів. Хоча тут так само писати код, проте він не буде збережений.
3. РОБОЧИЙ ПРОСТІР — тут зберігаються змінні, завантажені датасети та побудовані моделі. Крім того є окреме вкладинка історії останніх команд.
4. ГРАФІКИ та ФАЙЛИ — тут в окремих закладинках відображаються графіки, є невеличкий файловий менеджер, менеджер пакетів (про них трошки пізніше) та довідка по функціям (сюди будемо звертатися досить часто).
1.3 Базові операції
R - мова програмування з широкими можливостями. З її допомогою можна будувати математичні моделі, проводити статистичні тести, візуалізовувати дані тощо. Але почнемо з чогось максимально простого, наприклад, арифметики.
1.3.1 R та арифметика
Вже з “коробки,” без додаткових пакетів, R надає можливість проводити арифметичні розрахунки. Всі ці операції виконуються за допомогою типових операторів, до яких ми звикли ще з часів навчання в школі або викорситання Excel.
Так, додавання додавання двох чисел використовується оператор +:
2 + 2
## [1] 4Для віднімання — оператор -:
5 - 2
## [1] 3Множення через оператор *:
3 * 5
## [1] 15Ділення — /:
25 / 5
## [1] 5Піднесення до степеню через ^:
3 ^ 3
## [1] 27Як бачимо, нічого складного. Давайте розглянемо, ще два оператори.
Залишок від ділення — %%:
5 %% 3
## [1] 2Цілочисельне ділення — %/%:
17 %/% 5
## [1] 3Узагальнений перелік арифметичних операторів я помістив у наступну таблицю.
| Оператор | Опис | Пиклад |
|---|---|---|
| + | Додавання | a + b |
| - | Віднімання | a - b |
| * | Множення | a * b |
| / | Ділення | a / b |
| ^ | Степінь | a ^ b |
| %% | Залишок від ділення | a %% b |
| %/% | Цілочисельне ділення | a %/% b |
1.3.2 Коментарі до коду
Важливою складовою написання коду, окрім його зрозумілості та лаконічності, є коментарі, які допомагають оріентуватися, що відбувається в даному шматку коду.
Для додавання коментарів використовується знак ришітки або, як його ще називають, діез — #. Все, що написано у рядку після # ігнорується R:
# look at this awesome code
2 + 2 - 3 + 1
## [1] 2Якщо необхідно “закоментувати” частину коду, тобто поставити # на початку кожного рядка, то для цього є комбінація клавіш Ctrl + Shift + C.
1.3.3 Пріоритети розрахунків
Після знайомства з арифметикою в R постає логічне питання з приводу пріоритетів операторів. На справді тут все просто, пріоритети працюють як в математиці. Тож не забувайте правильно розставляти дужки.
2 + 3 * 4
## [1] 14
(2 + 3) * 4
## [1] 201.3.4 Готові функції
Крім звичайних арифметичних операторів в мові програмування R одразу вбудовано багато різноманітних функцій, в тому числі й математичних.
Для розрахунку кореня квадратного з числа використовується функція sqrt(), яка може бути вам знайома, якщо ви користувалися англомовною версією Excel.
9^0.5
## [1] 3
9^(1/2)
## [1] 3
sqrt(9)
## [1] 3Мова програмування R чутлива до регістру, тож варіанти Sqrt(9), SQRT(9) працювати не будуть.
Разом з тим, в середині функції можна проводити математичні розрахунки:
sqrt((2 + 3) * 4)
## [1] 4.472136Функція abs() розраховує абсолютне значення:
abs(3 - 5)
## [1] 2Розрахунок натурального логарифму через функцію log():
log(15)
## [1] 2.70805Але це ще не все, оскільки для логарифму притаманно мати основу, то в таких випадках слід додати в середині дужок додатковий аргумент base =:
log(x = 10, base = 3)
## [1] 2.095903Аргументи функцій можна змінювати місцями:
log(base = 3, x = 10)
## [1] 2.095903Доречі не обов’язково писати назви аргументів функцій. Якщо ви впевнені в їх порядку запис може виглядати наступним чином:
log(10, 3)
## [1] 2.095903Взагалі використання функцій — важлива особливість мови програмування R. Ми можемо створювати власні функції, використовувати функції як аргументи інших функцій тощо.
1.3.5 Вбудована документація
Вже на цьому етапі може виникнути ряд питань:
- де знайти опис функції?
- які існують аргументи функцій?
- чи є якісь приклади використання функцій?
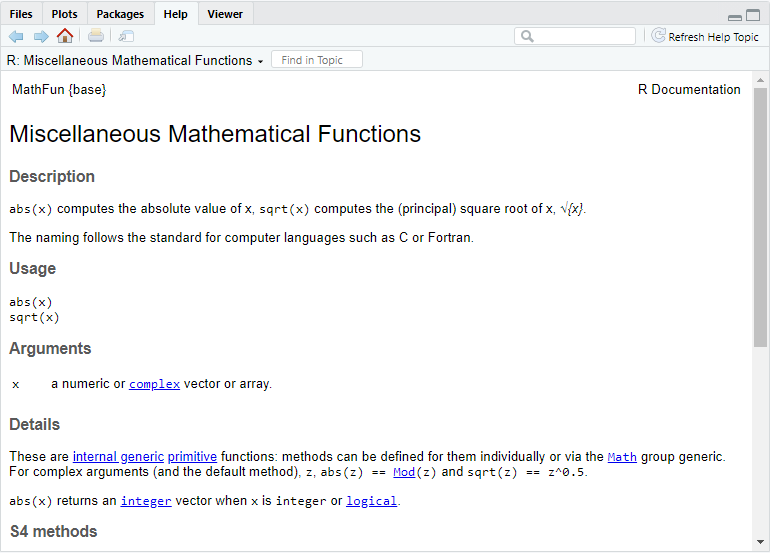
Відповідь досить проста — всі функції супроводжуються детальною документацією. Для її виклику можна скористуватися функцією help(), де в середині дужок вказати назву функції:
help(abs)Інший варіант — це написати в консолі знак питання і після цього назву функції:
?abs()Але на мою думку, найшвидший варіант — це написати функцію і натиснути клавішу F1 на клавіатурі.
Всі зазначені варіанти приведуть вас до вікна документації у правому нижньому куті RStudio:
1.3.6 Створення змінних
Ще один важливий пункт у багатьох мовах програмування — можливість зберігати значення у змінних.
В R це робиться за допомогою символів <-. Для швидкого написання існує зручна комбінація клавіш Alt + -.
Ліворуч від символу <- записується назва майбутньої змінної. Праворуч — значення або вираз, яке необхідно зберегти в цю змінну.
x <- 2
y <- 4
z <- sqrt(x^2 + y^3)Для присоювання можна використовувати і знак = але серед спільноти користувачів R це не прийнято.
Слід звернути увагу, що при присвоюванні результат розрахунку не виводиться в консоль. Якщо ж хочеться переглянути результат слід використати функцію print() або просто звернутися до створеної змінної:
print(z)
## [1] 8.246211
z
## [1] 8.246211
1.3.7 Оператори порівняння
В процесі роботи з даними, досить часто працюємо з задачами порівняння. Для вирішення таких питань в мові програмування R є зручні та зрозумілі оператори:
| Оператор порівняння | Опис | Приклад |
|---|---|---|
| == | Дорівнює | a == b |
| != | Не дорівнює | a != b |
| > | Більше | a > b |
| < | Менше | a < b |
| >= | Більше або дорівнює | a >= b |
| <= | Менше або дорівнює | a <= b |
Окремо зауважу, що для порівняння двох змінних використовується оператор з подвійним знаком дорівнює
==, а не з одним=. Це досить популярна помилка.
1.4 Типи даних
Інформація зберігається в різних структурах даних. Це може бути число, текст, булева змінна тощо.
Один з найпопулярніших варіантів збереження даних — це числовий формат. В мові програмування R для нього є окремий клас — numeric. При цьому існує три типи numeric:
- Цілі - integer.
- Дробові - double.
- Комплексні - complex.
В більшості випадків R буде сам конвертувати числа в потрібний формат. Але якщо необхідно задати конкретний тип числа, то можна використати функції as.integer(), as.double() та as.complex().
В мові програмування R досить багато функцій, які починаються на
as., які переводять об’єкт до конкретного класу. Іншими словами просить читати дані в середені дужок у відповідному форматі.
Для створення цілочислового значення можна в кінці поставити символ L, щоб примусово оголосити число як integer:
is.integer(10)
## [1] FALSE
is.integer(10L)
## [1] TRUEФункції, що починаються на
is.перевіряють, чи належить об’єкт до обраного класу.
Для роботи з текстовими даними є клас character. Вони записуються в лапках, при цьому можна використовувати як подвійні " так і одинарні '.
is.character("Ash nazg durbatulûk, ash nazg gimbatul,
ash nazg thrakatulûk, agh burzum-ishi krimpatul.")
## [1] TRUE-
Логічні (logical) данні - це тип даних які приймають лише значення
TRUEабоFALSE. Ми з ними вже зустрічалися коли використовували оператори порівняння.
Для перевірки типу даних використовується функція class():
class(5)
## [1] "numeric"1.5 Структури даних
R працює з багатьма структурами даних: вектори, матриці, масиви, дата фрейми та списки. Вони відрізняються за способом створення, структурою, складністю будови та способом звернення до їх елементів. Схематично ці структури даних зображено на рисунку 1.4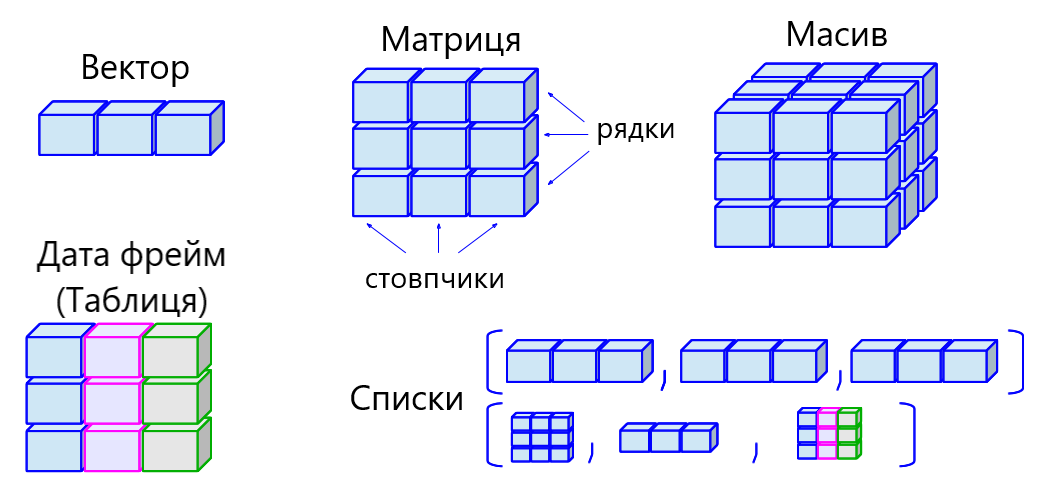
Рисунок 1.4: Структури даних R
1.5.1 Вектор
Почнемо з найпростішого. Вектор - це одновимірна послідовність елементів одного типу. Для створення вектору використовується функція c().
c(2, 4, 8, -2, -6, 0)
## [1] 2 4 8 -2 -6 0
c("два", "чотири", "шість")
## [1] "два" "чотири" "шість"
c(TRUE, TRUE, FALSE)
## [1] TRUE TRUE FALSEДля створення послідовностей з кроком 1 зручно використовувати оператор :
-5:5
## [1] -5 -4 -3 -2 -1 0 1 2 3 4 5
3:-2
## [1] 3 2 1 0 -1 -2Для складніших послідовностей є вбудована функція seq() (не забувайте дивитися довідку по функціях)
seq(1, 10, by = 2)
## [1] 1 3 5 7 9Крім того, можна задати не лише крок послідовності (аргумент by =), а й довжину (аргумент length.out =)
seq(1, 10, length.out = 3)
## [1] 1.0 5.5 10.0Інша корисна функція rep() дозволяє створити вектор з повторюваними значеннями. Перший аргумент - значення яке слід повторювати, другий аргумент - скільки разів повторювати.
rep(3, 5)
## [1] 3 3 3 3 3При цьому і перший і другий аргумент може бути вектором:
Крім того, можна об’єднувати вектори:
В означенні вектора в мові програмування R сказано, що всі елементи вектори мають бути одного типу. Одразу хочеться перевірити, що буде, якщо ця умова не буде виконуватись. В більшості мов програмування ми б отримали помилку. Мова програмування R, при розбіжності типів, буде зводити все до “спільного знаменника,” тобто конвертувати дані за певними правилами - приведення типів (coercion).
Виділяють два типи:
- неявне приведення типів (implicit coercion), коли все відбувається автоматично за вбудованими правилами.
- явне приведення типів (explicit coercion), коли ми самі вирішуємо до якого типу перевести дані, якщо це можливо.
Приклад неявного приведення типів:
c(TRUE, 2, FALSE)
## [1] 1 2 0
3 - TRUE
## [1] 2TRUE перетворився в 1, а FALSE в 0.
В цьому випадку всі дані приведено до текстового типу:
c(TRUE, 2, "Hello")
## [1] "TRUE" "2" "Hello"В R є своя ієрархія типів:
NULL < raw < logical < integer < double < complex < character < list < expression
Для явного приведення типів даних використовується сімейство функцій, що починається на as.:
as.numeric(c(TRUE, 2, FALSE, FALSE))
## [1] 1 2 0 0
as.character(c(TRUE, 2, FALSE, FALSE))
## [1] "1" "2" "0" "0"1.5.1.1 Операції з векторами
Всі арифметичні операції, що ми розглядали раніше, можна використовувати й до векторів однакової довжини:
q <- 1:5
w <- 2:6
q + w
## [1] 3 5 7 9 11
q - w
## [1] -1 -1 -1 -1 -1
q * w
## [1] 2 6 12 20 30
q / w
## [1] 0.5000000 0.6666667 0.7500000 0.8000000 0.8333333
w ^ q + q - w * q
## [1] 1 5 55 609 7751
sqrt(q)
## [1] 1.000000 1.414214 1.732051 2.000000 2.2360681.5.1.2 Правило переписування
Якщо вектори не однакової довжини й ми хочемо провести з ними певні операції, то в такому випадку спрацює правило переписування (recycling rule): якщо коротший вектор кратний довжині довшого, короткий буде повторюватися необхідну кількість разів.
q <- 1:2
w <- 1:4
q * w
## [1] 1 4 3 8Операції з вектором та окремим значенням можна вважати окремим випадком рестайлінгу: окреме значення буде повторюватися необхідну кількість разів:
w * 2
## [1] 2 4 6 8Якщо коротший вектор не кратний довшому (наприклад, перший довжиною 2, а інший - 3), то R все одно порахує результат, але видасть попередження:
q + c(1, 5, 7)
## Warning in q + c(1, 5, 7): longer object length is not a multiple of shorter object
## length
## [1] 2 7 81.5.1.3 Індексація векторів
Індексація - задача вибору окремого елемента структури даних. Для цього використовуються квадратні дужки [].
Найпростіший варіант індексація по номеру, тобто порядкове значення елемента:
e <- c(-5:-3, 2, 7, -6, 4:2)
e[1]
## [1] -5
e[5]
## [1] 7Важливий факт - індексація в мові програмування R починається з 1.
За допомогою індексації можна не лише звертатися до окремого елементу, а й заміняти його значення:
e[5] <- 15Можна використовувати цілі вектори для індексації:
e[2:5]
## [1] -4 -3 2 15
e[6:1]
## [1] -6 15 2 -3 -4 -5Індексація зі знаком мінус видасть всі значення вектора крім обраних:
e[-1]
## [1] -4 -3 2 15 -6 4 3 2
e[c(-1, -5)]
## [1] -4 -3 2 -6 4 3 21.5.2 Матриці
Матриця (matrix) — це двовимірний масив даних, в якому кожен елемент має однаковий тип (числовий, текстовий, логічний). Іншими словами, матриця - це двовимірний вектор, у якого є довжина та ширина.
Створення матриці відбувається за допомогою функції matrix(), в якій слід вказати кількість рядків та стовпчиків:
matrix(1:16, nrow = 4, ncol = 4)
## [,1] [,2] [,3] [,4]
## [1,] 1 5 9 13
## [2,] 2 6 10 14
## [3,] 3 7 11 15
## [4,] 4 8 12 16За замовчуванням значення матриці заповнюються по стовпчиках. Але це можна змінити за допомогою аргументу byrow = TRUE
matrix(1:16, nrow = 4, ncol = 4, byrow = TRUE)
## [,1] [,2] [,3] [,4]
## [1,] 1 2 3 4
## [2,] 5 6 7 8
## [3,] 9 10 11 12
## [4,] 13 14 15 16Оскільки матриця — це двовимірний масив, то для індексації використовуються два індекси, що розділені комою: перший відповідає за рядок, другий за стовпчик.
my_matrix <- matrix(1:16, nrow = 4, ncol = 4)
my_matrix
## [,1] [,2] [,3] [,4]
## [1,] 1 5 9 13
## [2,] 2 6 10 14
## [3,] 3 7 11 15
## [4,] 4 8 12 16
my_matrix[2, 3]
## [1] 10
my_matrix[1:2, 3:4]
## [,1] [,2]
## [1,] 9 13
## [2,] 10 14Якщо один з індексів залишити пустим — отримаємо всі значення рядка/стовпчика в залежності від того, який індекс ми не вказуємо.
my_matrix[, 1:2]
## [,1] [,2]
## [1,] 1 5
## [2,] 2 6
## [3,] 3 7
## [4,] 4 8
my_matrix[1:2, ]
## [,1] [,2] [,3] [,4]
## [1,] 1 5 9 13
## [2,] 2 6 10 14Аналогічно до вектора, за допомогою індексації можна переписувати частину матриці:
my_matrix[1:2, 3:4] <- 0
my_matrix
## [,1] [,2] [,3] [,4]
## [1,] 1 5 0 0
## [2,] 2 6 0 0
## [3,] 3 7 11 15
## [4,] 4 8 12 161.5.3 Масиви
Масиви даних (array) — схожі на матриці, але мають понад два виміри. Створюються вони за допомогою функції array(), де слід вказати вектор, з якого буде створено масив, і його розмірність:
1.5.4 Списки
Списки — це впорядкований набір об’єктів. Я представляю собі списки, як блокнот, в якому на кожній сторінці зберігається інформація у певному форматі. Вони можуть зберігати різні дані, в тому числі вектори, матриці, дата фрейми й інші списки.
Списки створюються за допомогою функції list():
my_list <- list(vec = c(1:5),
gendalf = "You shall not pass",
my_matrix = matrix(1:4, ncol = 2))
my_list
## $vec
## [1] 1 2 3 4 5
##
## $gendalf
## [1] "You shall not pass"
##
## $my_matrix
## [,1] [,2]
## [1,] 1 3
## [2,] 2 4В цьому випадку vec, gendalf та my_matrix — назви елементів списку.
Для звернення до елементів списку можна використовувати індекси або імена (через символ $). При зверненні через індекс необхідно використовувати подвійні квадратні дужки, наприклад:
my_list[[2]]
## [1] "You shall not pass"
my_list$gendalf
## [1] "You shall not pass"
my_list[['gendalf']]
## [1] "You shall not pass"Списки досить часто використовуються в R, наприклад результати побудови математичних моделей, статистичних тестів зберігаються у вигляді списків. тож важливо вміти з ними працювати.
1.5.5 Дата фрейми
Нарешті ми перейшли до найголовнішого - дата фрейми (data frames). Саме з такою структурою даних працюють найчастіше. Головною особливістю їх є те, що різні стовпчики можуть містити різний тип даних (але їх довжина має бути однаковою).
Для створення дата фрейму використовується функція data.frame().
my_df <- data.frame(name = c("Frodo", "Eowyn", "Legolas", "Arwen"),
sex = c("male", "female", "male", "female"),
age = c(51, 24, 2931, 2700),
one_ring = c(TRUE, FALSE, FALSE, FALSE))
my_df| name | sex | age | one_ring |
|---|---|---|---|
| Frodo | male | 51 | TRUE |
| Eowyn | female | 24 | FALSE |
| Legolas | male | 2931 | FALSE |
| Arwen | female | 2700 | FALSE |
Переглянути структуру дата фрейму можна за допомогою функції str():
str(my_df)
## 'data.frame': 4 obs. of 4 variables:
## $ name : chr "Frodo" "Eowyn" "Legolas" "Arwen"
## $ sex : chr "male" "female" "male" "female"
## $ age : num 51 24 2931 2700
## $ one_ring: logi TRUE FALSE FALSE FALSEВ нашому випадку перший та другий стовпчик - текстові, третя - числова, четверта - логічна.
Переглянути назви стовпців або надати їм нову назву можна за допомогою функції names().
names(my_df)
## [1] "name" "sex" "age" "one_ring"Індексація аналогічно до матриці та списків можлива через [] та знак $.
my_df$name
## [1] "Frodo" "Eowyn" "Legolas" "Arwen"
my_df$name[2:3]
## [1] "Eowyn" "Legolas"
my_df[2,3]
## [1] 24
my_df[2:3, "name"]
## [1] "Eowyn" "Legolas"Для перегляду дата фрейму в RStudio використовується функція View() або можна просто натиснути на назву змінної у розділі Environment. Ви побачите таблицю, дещо схожу на Excel або Google Spreadsheets.
1.5.6 Фактори
Фактори (factor) - спеціальний клас даних для збереження номінативних (якісних) змінних. Це можуть бути групи клієнтів, стать, якість обслуговування тощо.
Для створення таких змінних використовується функція factor():
race <- factor(
c("istari", "human", "human",
"elf", "dwarf", "hobbit",
"hobbit", "hobbit", "hobbit"),
levels = c("istari", "human", "elf", "dwarf", "hobbit")
)
race
## [1] istari human human elf dwarf hobbit hobbit hobbit hobbit
## Levels: istari human elf dwarf hobbitПри цьому всередині факторів можна зберігати впорядковані номінативні дані. Для цього необхідно вказати аргумент ordered = TRUE:
lotr_books <- factor(c("The Fellowship of the Ring",
"The Return of the King",
"The Two Towers"),
levels = c("The Fellowship of the Ring",
"The Two Towers",
"The Return of the King"),
ordered = TRUE)
lotr_books
## [1] The Fellowship of the Ring The Return of the King The Two Towers
## Levels: The Fellowship of the Ring < The Two Towers < The Return of the King1.6 Пакети в R
R - мова програмування з дуже широкими можливостями. Однак рано чи пізно ми почнемо стикатися з задачами, які потребуватимуть додаткових можливостей. Ці можливості можна розширити за допомогою додаткових пакетів (packages).
В більшості випадків основним змістом пакетів є набір додаткових функцій, даних або нових структур даних.
До найпопулярніших пакетів у сфері науки про дані (data science) можна віднести екосистему пакетів tidyverse, пакети data.table, mlr3 та ще багато-багато інших.
1.6.1 Вбудовані пакети
Разом з самою мовою програмування R поставляються пакети, які не потрібно встановлювати: основний base та декілька інших, такі як stats, utils, graphics та інші. Повний перелік можна переглянути за наступним кодом:
rownames(installed.packages(priority = "base"))
## [1] "base" "compiler" "datasets" "graphics" "grDevices" "grid"
## [7] "methods" "parallel" "splines" "stats" "stats4" "tcltk"
## [13] "tools" "utils"1.6.2 Встановлення пакетів з CRAN
Пакети які пройшли перевірку зберігаються в Comprehensive R Archive Network (CRAN). Для перегляду кількості опублікованих пакетів на CRAN можна використати наступний код:
nrow(available.packages())
## [1] 18564І з кожним роком їх стає все більше:
 Функція
Функція install.packages() дозволяє звантажувати та встановлювати пакети з CRAN. Для прикладу встановимо пакет vroom, для зчитування файлів
install.packages("vroom")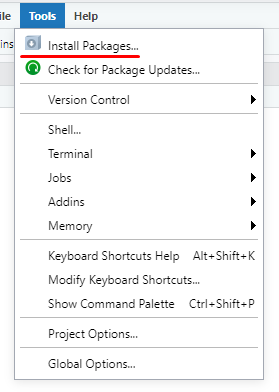
Рисунок 1.5: Меню встановлення пакетів в RStudio
Або через кнопку в розділі Packages (рис. 1.6)
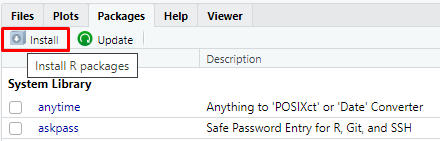
Рисунок 1.6: Кнопка встановлення пакетів
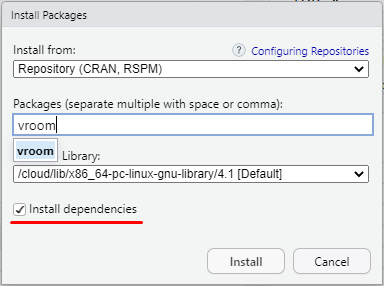
Рисунок 1.7: Меню встановлення пакетів
1.6.3 Встановлення пакетів з GitHub
Бувають випадки, коли автори пакетів не пройшли або не захотіли проходити перевірку через CRAN (насправді причин може бути безліч). В таких випадках пакет (який ви напевно знайшли через пошук в Google) скоріш за все буде зберігатися на репозиторію GitHub. Для таких випадків нам необхідно встановити пакет devtools та використати з нього функцію install_github(). Покажу на прикладі пакету xaringan, який я використовую для створення інтерактивних презентацій.
devtools::install_github('yihui/xaringan')Посилання yihui/xaringan — це адреса пакету в GitHub
1.6.4 Підключення пакетів
Після завантаження пакета, для того щоб почати користуватися його функціоналом необхідно його підключити до поточної сесії. Для цього використовується функція library(). Назву пакету можна писати як в лапках так і без них.
Як правило, підключення пакетів записується на початку скрипта, що дає можливість зрозуміти який інструментарій використовується в ньому.
1.6.5 Виклик функції через ::
У випадках, коли функцію з пакету буде використано вcього декілька разів, є сенс не підключати весь пакет, а завантажити тільки окрему його функцію. Для цього використовується спеціальний оператор ::, ліворуч від якого вказується назва пакету, а праворуч відповідна функція з обраного пакету.
vroom::vroom_example()Крім того оператор :: корисний у випадках, коли в різних пакетах присутні функції з однаковою назвою. Наприклад в пакеті dplyr є функція filter(). Функція з такою ж назвою є в базовому пакеті stats, який використовується у зовсім інших задачах. В таких просто вкажіть з якого пакету ви хочете використати функцію:
Пріоритет надається функціоналу пакету, який був підключений останній.